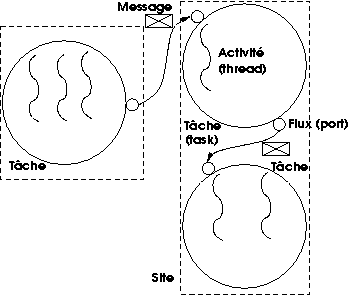
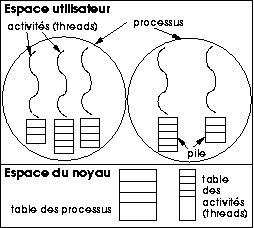
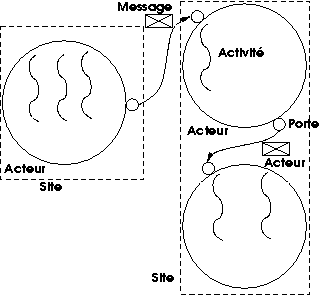
Au-dessus du noyau les créateurs de Chorus ont développé un ensemble de serveurs destinés à constituer un sous-système Unix, tel que représenté par la figure 10.3. Chaque type de ressource du système (processus, fichier...) est géré par un serveur système dédié. Les serveurs peuvent résider sur des sites différents : on voit que Chorus, encore plus que Mach, a été conçu dans la perspective de construction de systèmes répartis. Ce découpage du noyau Unix en serveurs modulaires était très intéressant tant du point de vue du génie logiciel (l'art de construire de grands systèmes informatiques) que de celui de l'architecture. L'entreprise a (partielllement) achopé sur la difficulté à restituer la sémantique du noyau Unix dans un contexte non monolithique, ainsi que sur des problèmes de performances. Tant que l'on en reste à un site unique, Chorus implémente des appels de procédures à distance (RPC, pour Remote Procedure Call) légers, mais cette solution n'est disponible que si l'on renonce à la répartition, et pour des processus en mode superviseur. La réalisation efficace de communications inter-processus par passage de messages ne viendra qu'après le rachat de Chorus par Sun, et ce sera une autre équipe qui s'en acquittera.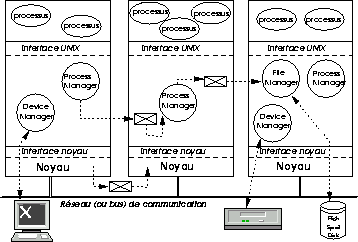
Le projet Mach à l'Université Carnegie-Mellon s'est arrêté en 1994, mais il a une postérité réelle. L'Université d'Utah a repris le flambeau pendant quelques années. Le projet GNU Hurd vise à remplacer le noyau Unix par une collection de serveurs implantés au-dessus d'un noyau Mach. Le système MacOS-X d'Apple, et dans une certaine mesure le noyau de Tru64 Unix de Compaq (ex-Digital) sont des descendants plus ou moins légitimes du micro-noyau Mach au-dessus duquel Apple et Compaq ont implanté des systèmes Unix de sensibilité plutôt BSD.