par Laurent Bloch
Les archaïsmes hérités des mémoires auxiliaires électromécaniques et de la notion de fichier qui leur est consubstantielle sont tellement ancrés dans les esprits que l’on n’en finit pas de découvrir et d’exploiter les avantages des mémoires persistantes à semi-conducteurs (SSD). Il y a déjà une dizaine d’années la méthode d’accès NVMe permettait de s’affranchir du protocole SATA des disques rotatifs et de connecter physiquement les SSD à un bus PCI Express par l’interface Northbridge de la carte mère, avec des gains de performance de trois ordres de grandeur par rapport à l’électromécanique. Dans un article plus récent je rendais compte d’un article des Communications of the Association for Computing Machinery (CACM), Offline and Online Algorithms for SSD Management, où Tomer Lange, Joseph (Seffi) Naor et Gala Yadgar proposaient de nouveaux algorithmes pour encore améliorer les accès à ces types de mémoire.
Mais sur ces entrefaites un lecteur anonyme mais avisé me faisait remarquer que cet article et ces commentaires négligeaient le cas des Systèmes de gestion de bases de données (SGBD), qui n’utilisent généralement pas pour accéder aux mémoires externes les protocoles standard procurés par le système d’exploitation, mais des protocoles spécifiques. Ce lecteur me signalait un excellent article publié en 2019 dans les Proceedings of the VLDB Endowment [1] par Aarati Kakaraparthy, Jignesh M. Patel, Kwanghyun Park et Brian P. Kroth, Optimizing Databases by Learning Hidden Parameters of Solid State Drives, accessible en ligne sous licence Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 et consacré à ce sujet.
Mademoiselle Aarati Kakaraparthy (j’aurai appris qu’Aarati était un prénom féminin en Inde, en langue tamoul je pense) et ses collègues ont conduit des expériences systématiques avec deux logiciels libres de gestion de bases de données, SQLite et MariaDB, et avec quatre modèles de SSD :
| Nom | Technologie | Capacité | Interface |
| Samsung 960 EVO | SSD Flash | 512 GB | NVMe |
| Intel Optane 905P | 3D XPoint | 480 GB | NVMe |
| Toshiba XG5 | SSD Flash | 256 GB | NVMe |
| Micron M500 | SSD Flash | 120 GB | SATA |
On note la présence de la technologie de mémoire à changement de phase (PCM) Intel 3D XPoint, annoncée en 2015 et abandonnée en 2022 pour cause de rentabilité insuffisante, mais qui avait des caractéristiques intéressantes : elle était adressable octet par octet, ne nécessitait pas l’effacement avant la réécriture, ses performances et ses prix étaient intermédiaires entre ceux de la mémoire centrale et ceux des SSD, elle s’usait moins vite que ces derniers. Son abandon est sans doute la conséquence de l’échec du partenariat avec Micron ; on peut aussi penser qu’Intel a lui-même tué sa créature en la dotant d’une interface fermée inaccessible aux autres industriels, nommée Optane. On lira avec intérêt à ce sujet une analyse de Jim Handy Mais les idées de 3D XPoint réapparaîtront sans doute un jour.
La première étape de la démarche de nos auteurs consiste à détecter les paramètres internes propres à chaque modèle de SSD. En effet l’architecture interne des SSD est fortement hiérarchique, connaître l’organisation de cette hiérarchie est nécessaire à l’optimisation, les constructeurs ne la divulguent pas, il faut donc s’en remettre à l’observation extérieure pour l’en déduire.
Principes d’organisation des SSD
L’organisation hiérarchique interne des SSD permet d’effectuer certaines opérations en parallèle, ce qui accroît les performances du système. Cette organisation varie d’un modèle à l’autre, mais elle obéit aux schémas de principe des figures ci-contre.
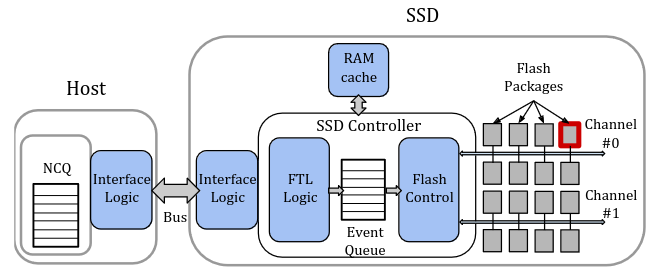

L’ordinateur hôte (Host sur la première figure) gère une file d’attente (Native Command Queuing, NCQ) des commandes d’accès au SSD, auquel il les transmet selon le protocole d’interface logique (NVMe ou SATA), éventuellement après les avoir réorganisées pour qu’elles soient exécutées dans un ordre optimal. Les commandes sont prises en compte par le contrôleur SSD, doté d’une mémoire RAM (rapide et volatile) qui sert de mémoire cache et permet la bufferisation des opérations et les calculs internes. La FTL ( Flash Translation Layer) traduit les adresses logiques des données (emplacement dans le fichier ou dans la base de données) en adresse physiques.
Le contrôleur SSD commande plusieurs canaux d’accès, qui sont des bus (c’est-à-dire des graphes connexes complets, des dispositifs qui permettent à tous les éléments connectés de communiquer entre eux). Chaque canal accède à plusieurs flash packages, lesquels rassemblent plusieurs chips ; chaque chip est organisés en plans, subdivisés en blocs, eux-mêmes subdivisés en pages de 2 à 16 KB. Un bloc typique de 2MB peut par exemple contenir 128 pages.
La version la plus récente d’une page est considérée valide ; toutes les autres versions sont invalides. À un instant t, tout emplacement (slot) du SSD est de façon déterministe dans un des états suivants : valide, invalide ou propre (clean). Un emplacement est valide s’il contient la version valide d’une page. Un emplacement valide qui contient la page p devient invalide en cas de modification de la page p. Et après un effacement du bloc b tous les emplacements de b sont propres (clean).
L’unité de lecture de données est la page. L’opération d’écriture est plus compliquée : l’écriture dans une page de SSD nécessite la réécriture d’un bloc entier [2]. Avant de modifier une page, il faut donc lire le bloc qui la contient, sauvegarder ailleurs les pages de ce bloc qui contiennent des données valides, invalider le bloc, modifier la page considérée conformément à la commande d’écriture, réécrire le ou les blocs modifiés, mettre à jour les tables de correspondance entre adresses logiques et physiques.
Plusieurs canaux peuvent transférer des données simultanément ; à un instant donné un canal ne peut accéder qu’à un flash package, mais les commandes destinées à plusieurs packages d’un même canal peuvent être intercalées de sorte qu’elles soient exécutées simultanément. Afin de transférer simultanément des données reliées entre elles, pour un meilleur débit, il peut être judicieux de les répartir dans des blocs connectés à des canaux différents, ce qui nécessite une connaissance détaillée de l’organisation interne du SSD.
Et enfin ne pas oublier que l’opération d’écriture nécessite au moins une opération d’effacement d’un bloc, et que ces dernières usent physiquement l’emplacement, à cause de la tension élevée qui doit lui être appliquée pour l’effacer. Après quelques dizaines de milliers d’effacements, le composant est hors service.
Recommandations générales
Antérieurement à ce travail, divers auteurs avaient déjà émis des recommandations générales pour l’utilisation des SSD :
– écrire par « gros morceaux », ou en séquence, pour limiter le morcellement de l’espace d’adressage ;
– écrire à des emplacements voisins les données qui risquent d’être utilisées à des instants proches dans le temps ;
– lire par « gros morceaux » et en séquence ;
– écrire à des adresses alignées sur des frontières de pages, des « morceaux » de taille multiple de la taille de page.
À la découverte des paramètres cachés
Pour découvrir les paramètres d’organisation interne des appareils étudiés, nos auteurs ont dû accomplir de laborieuses campagnes de mesures, en effectuant de multiples opérations de lecture et d’écriture avec des configurations différentes de taille des données et de leur disposition, et en observant les temps de réponse. Les paramètres internes ainsi découverts sont au nombre de cinq :
– les longueurs de données souhaitables (qui donnent de bonnes performances) pour les opérations d’écriture ;
– la longueur de bande (stripe size), qui est l’unité élémentaire pour l’organisation physique des données à l’intérieur du SSD ;
– la taille de fragment (chunk size), qui est la quantité de données contiguës sur un canal unique ;
– la taille de page ;
– les bons alignements (hot locations) de l’espace adresse logique, soit les frontières d’adresses souhaitables pour les commandes.
Voici les résultats (i est un nombre entier) :
| Nom | Longueur d’écriture | Longueur | Taille de | Bons | Taille de |
| souhaitable | de bande | fragment | alignements | page | |
| Samsung 960 EVO | 32KB×i | 64KB | 64KB | 64KB×i+32KB | - |
| Intel Optane 905P | 1KB×i | - | 4KB | 4KB×i | 4KB |
| Toshiba XG5 | 64KB×i | 64KB | 4KB | 4KB×i | 4KB |
| Micron M500 | 64KB×i | 64KB | 4KB | 4KB×i | 4KB |
Il en ont inféré les règles que je résume ci-dessous, et auxquelles ils se proposent d’adapter les réglages des SGBD :
– émettre des commandes d’écriture de longueurs multiples de la longueur d’écriture souhaitable minimum ;
– dans la mesure du possible, émettre des commandes de lecture de la taille de fragment, alignées sur les bonnes positions ;
– émettre des commandes d’écriture alignées sur des frontières de bandes, de préférence de la longueur de la bande ;
– ne pas émettre des commandes d’écriture de la taille de fragment non alignées, ce qui détruirait complètement la régularité des bons alignements ;
– émettre des commandes d’écriture qui modifient le moins de pages possibles.
Après les essais
La description du processus expérimental montre qu’Aarati Kakaraparthy n’a vraiment pas hésité à plonger les mains dans le cambouis (on peut supposer que c’était elle, parce qu’à l’époque Jignesh M. Patel était son directeur de thèse, cependant que Kwanghyun Park et Brian P. Kroth travaillaient chez Microsoft, où elle avait pu effectuer un stage pratique). Je vous renvoie à l’article pour les aventures des 10 millions de couples clé-valeur de la base initiale, des 50 000 insertions et des 50 000 requêtes aléatoires, réitérées avec des tailles de transaction différentes. Les fichiers de journalisation (log files) se sont avérés sources de problèmes intéressants, pour SQLite il a fallu en modifier le format parce que le format standard détruisait complètement les « bons » alignements, avec par conséquent un facteur d’amplification d’écriture désastreux. Les développements sur le fichier index organisée en arbre B+ (B+ Tree) sont aussi l’occasion de fructueuses révisions [3]. De beaux schémas aident à comprendre les adaptations qu’il a fallu apporter aux paramètres standard pour obtenir de bonnes performances. Ces adaptations ont nécessité la modification des modules d’entrée-sortie des SGBD. Bref, dès que l’on analyse en détail leur fonctionnement, les SGBD se révèlent des objets singulièrement complexes.
Au bout du compte, les modifications apportées aux modules d’entrée-sortie des SGBD ont permis, selon les appareils et selon le SGBD (SQLite3 ou MariaDB), des gains en débit pour les opérations de type SELECT de 29% et 27% respectivement. C’est le résultat le plus significatif, parce qu’en définitive l’ajustement des paramètres des opérations d’écriture a pour but principal l’amélioration des performances en lecture des données concernées. Il convient de saluer le travail d’Aarati Kakaraparthy et de ses co-auteurs, non seulement pour les résultats concrets obtenus, mais surtout à mon avis pour la compréhension en profondeur qu’ils apportent du fonctionnement des appareils et des logiciels étudiés et de leurs interactions, ce qui me semble ouvrir une voie prometteuse à des travaux ultérieurs.