Cet article est la transcription de la séance du Séminaire Codes sources que j’ai donnée le 30 janvier 2020, à l’invitation de Baptiste Mélès, pour répondre à la question de savoir quel langage utiliser pour enseigner la programmation. Il fait suite à l’article Python et Biopython.
La programmation fonctionnelle est un assaut radical et élégant contre toute la pratique de l’écriture de programmes. Elle s’écarte totalement de la mentalité du programmeur qui « fait ci et puis après fait ça ». Vous devez recâbler votre cerveau d’une façon assez différente.
« Faire ci et puis après faire ça »
C’est la tendance spontanée du programmeur débutant, encouragée par le style de beaucoup de langages, surtout en mode interprété.
En général cela finit de façon horrible, ainsi :
x = int(input("Entrez la valeur de x : "))
y = int(input("Entrez la valeur de y : "))
if x != 0:
y = x + x**2
y = (y - 3) // x
if y != 0:
y = y % x
print (x, y)Cette façon de faire est peu satisfaisante. Tous ceux qui utilisent Python pour enseigner sérieusement la programmation sont d’accord sur le fait qu’il faut interdire la fonction input.
Pour construire un programme il faut...
Corrado Böhm et Giuseppe Jacopini on montré en 1966 que tout algorithme pouvait être programmé avec trois constructions :
– séquence d’instructions ;
– alternative ;
– répétitive.
Ce résultat est au fondement de la programmation structurée des années 1970, une étape considérable dans l’art de la programmation, qui énonce qu’une qualité éminente d’un programme sera sa lisibilité par un être humain, et qui préconise de ce fait le renoncement à l’instruction go to.
Leur article est une des deux références de celui de Dijkstra, Go to Statement Considered Harmful (1968) (l’autre est un article de Wirth et Hoare sur Algol).
Environnement de programmation
Voici ce que présente à son utilisateur un environnement de programmation assez représentatif de ce qui se fait.


C’est assez commode d’usage, mais un univers fermé.
Finalement, avec Biopython :
Voici ce que l’utilisateur profane de Biopython est enclin à écrire pour visiter une séquence biologique, ici de protéine, issue de la banque classique SwissProt :
#!/usr/bin/env python3
from Bio import ExPASy
from Bio import SeqIO
with ExPASy.get_sprot_raw("O23729") as handle:
seq_record = SeqIO.read(handle, "swiss")
print(seq_record.id)
print(seq_record.name)
print(seq_record.description)
print(repr(seq_record.seq))
print("Length %i" % len(seq_record))
print(seq_record.annotations["keywords"])Biopython répond :
O23729
CHS3_BROFI
RecName: Full=Chalcone synthase 3; EC=2.3.1.74; AltName:
Full=Naringenin-chalcone synthase 3;
Seq('MAPAMEEIRQAQRAEGPAAVLAIGT...GAE', ProteinAlphabet())
Length 394
['Acyltransferase', 'Flavonoid biosynthesis', 'Transferase']Recherche de séquences
#!/usr/bin/env python3
def FetchSeqMulti(mydb, myrettype, myretmode, myid):
from Bio import Entrez
from Bio import SeqIO
Entrez.email = "lb@laurentbloch.org"
with Entrez.efetch(db=mydb, rettype=myrettype,\
retmode=myretmode, id=myid) as handle:
for seq_record in SeqIO.parse(handle, "gb"):
print("%s %s..." % (seq_record.id,\
seq_record.description[:50]))
print("Sequence length %i, %i features, from: %s"
% (len(seq_record), len(seq_record.features),\
seq_record.annotations["source"]))
FetchSeqMulti("nucleotide", "gb", "text",\
"6273291,6273290,6273289")ce qui donne :
AF191665.1 Opuntia marenae rpl16 gene; chloroplast gene for c...
Sequence length 902, 3 features, from: chloroplast Grusonia marenae
AF191664.1 Opuntia clavata rpl16 gene; chloroplast gene for c...
Sequence length 899, 3 features, from: chloroplast Grusonia clavata
AF191663.1 Opuntia bradtiana rpl16 gene; chloroplast gene for...
Sequence length 899, 3 features, from: chloroplast Grusonia bradtianaLes principales banques de séquences sont :
– GenBank (61 millions de séquences) et EMBL pour les séquences nucléotidiques ;
– UniProt, Swiss-Prot (561 568 séquences) et TrEMBL pour les protéines ;
– PDB, SCOP et CATH fournissent des informations de structure spatiale des protéines, nécessaires aux logiciels de modélisation moléculaire ;
– PubMed est une banque de données bibliographiques.
Code génétique
Le génome est codé dans un alphabet à quatre lettres, A (adénine), C (cytosine), T (thymine), G (guanine) de l’ADN, les nucléotides. Un gène (un ou plusieurs mots du génome), pour être exprimé, doit d’abord être transcrit en ARN messager (même séquence que l’ADN en remplaçant le T de la thymine par U de l’uracile), qui va le transmettre au mécanisme de traduction cellulaire.
Le génome permet la biosynthèse de protéines. Un gène codé dans l’ADN est transcrit en ARN par l’enzyme ARN polymérase, nucléotide pour nucléotide en remplaçant le T (thymine) de l’ADN par le U (uracile) de l’ARN. Ce brin d’ARN messager est ensuite traduit en protéine par le ribosome, un organe de la cellule qui assemble les acides aminés pour former les protéines conformément au code génétique. C’est ainsi que les protéines (éventuellement toxiques pour l’hôte) encodées dans l’ADN d’un virus sont synthétisées par le mécanisme cellulaire de l’hôte.
Les acides aminés constitutifs des protéines présentes dans les organismes vivants sont au nombre de 20. Pour désigner 20 entités différentes avec un alphabet de 4 caractères il faut 3 caractères. Les parties codantes du génome sont donc traduites par groupes de 3, les codons. Un codon de trois nucléotides permettrait de désigner 64 acides aminés, mais il n’y en a que 20 : certains acides aminés sont désignés par plusieurs codons, le code génétique est un code dégénéré.
Acides aminés
Ci-dessous la liste des acides aminés, leurs noms et leurs abréviations, suivis des codons (ici d’ARN) qui codent pour chacun.
Alanine A Ala GCU, GCC, GCA, GCG.
Arginine R Arg CGU, CGC, CGA, CGG ; AGA, AGG.
Asparagine N Asn AAU, AAC.
Acide aspartique D Asp GAU, GAC.
Cystéine C Cys UGU, UGC.
Glutamine Q Gln CAA, CAG.
Acide glutamique E Glu GAA, GAG.
Glycine G Gly GGU, GGC, GGA, GGG.
Histidine H His CAU, CAC.
Isoleucine I Ile AUU, AUC, AUA.
Leucine L Leu UUA, UUG ; CUU, CUC, CUA, CUG.
Lysine K Lys AAA, AAG.
Méthionine M Met AUG.
Phénylalanine F Phe UUU, UUC.
Proline P Pro CCU, CCC, CCA, CCG.
Pyrrolysine O Pyl UAG, avant élément PYLIS.
Sélénocystéine U Sec UGA, avec séquence SECIS.
Sérine S Ser UCU, UCC, UCA, UCG ; AGU, AGC.
Thréonine T Thr ACU, ACC, ACA, ACG.
Tryptophane W Trp UGG. (UGA)
Tyrosine Y Tyr UAU, UAC.
Valine V Val GUU, GUC, GUA, GUG.
Initiation AUG. (UUG, CUG)
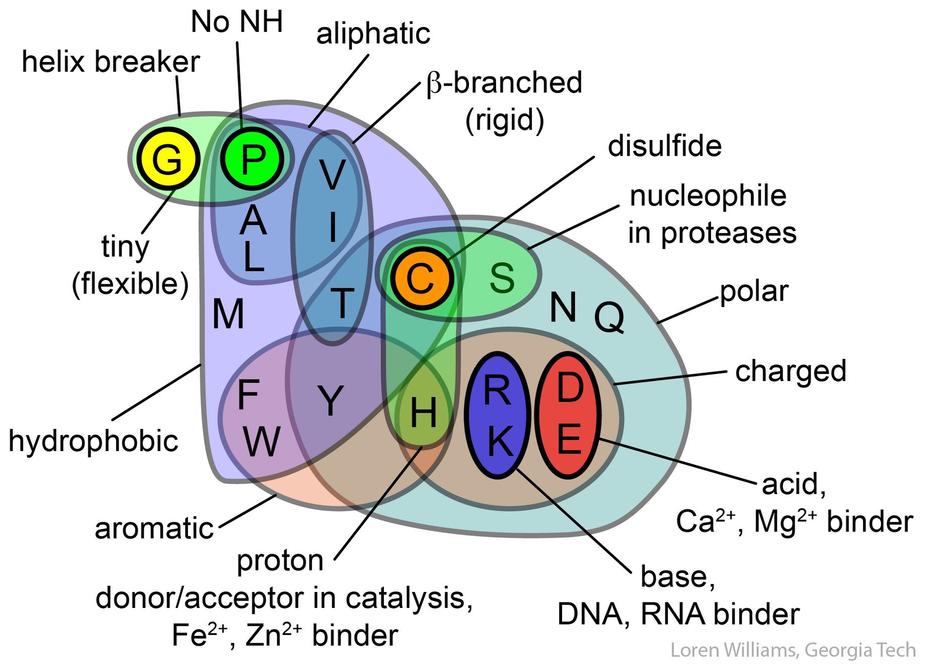
Terminaison * UAG, UAA ; UGA.Ci-dessous un diagramme, emprunté au professeur Loren Williams, de Georgia Tech, qui résume les principales propriétés des acides aminés :
Avez-vous déjà vu une protéine ?
Une vraie protéine, pas celles que vous trouvez dans les distributeurs de boisson des salles de gymnastique.
En voici une, issu d’un xénope tropical, sorte de crapaud griffu africain aimé des biologistes pour certaines propriétés intéressantes :
ID 1433B_XENTR Reviewed; 244 AA.
AC Q5XGC8; Q28HK2;
DT 22-NOV-2005, integrated into UniProtKB/Swiss-Prot.
DT 23-NOV-2004, sequence version 1.
DT 28-NOV-2006, entry version 18.
DE 14-3-3 protein beta/alpha.
GN Name=ywhab;
OS Xenopus tropicalis (Western clawed frog) (Silurana tropicalis).
OC Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi;
OC Amphibia; Batrachia; Anura; Mesobatrachia; Pipoidea; Pipidae;
OC Xenopodinae; Xenopus; Silurana.
OX NCBI_TaxID=8364;
RN [1]
RP NUCLEOTIDE SEQUENCE [LARGE SCALE MRNA].
RG Sanger Xenopus tropicalis EST/cDNA project;
RL Submitted (MAR-2006) to the EMBL/GenBank/DDBJ databases.
RN [2]
RP NUCLEOTIDE SEQUENCE [LARGE SCALE MRNA].
RC TISSUE=Embryo;
RG NIH - Xenopus Gene Collection (XGC) project;
RL Submitted (OCT-2004) to the EMBL/GenBank/DDBJ databases.
CC -!- FUNCTION: Adapter protein implicated in the regulation of a large
CC spectrum of both general and specialized signaling pathway. Binds
CC to a large number of partners, usually by recognition of a
CC phosphoserine or phosphothreonine motif. Binding generally results
CC in the modulation of the activity of the binding partner (By
CC similarity).
CC -!- SUBUNIT: Homodimer (By similarity).
CC -!- SUBCELLULAR LOCATION: Cytoplasm (By similarity).
CC -!- SIMILARITY: Belongs to the 14-3-3 family.
CC -----------------------------------------------------------------------
CC Copyrighted by the UniProt Consortium, see http://www.uniprot.org/terms
CC Distributed under the Creative Commons Attribution-NoDerivs License
CC -----------------------------------------------------------------------
DR EMBL; CR760847; CAJ82973.1; -; mRNA.
DR EMBL; BC084514; AAH84514.1; -; mRNA.
DR UniGene; Str.8742; -.
DR SMR; Q5XGC8; 1-231.
DR Ensembl; ENSXETG00000022830; Xenopus tropicalis.
DR InterPro; IPR000308; 14-3-3.
DR Gene3D; G3DSA:1.20.190.20; 14-3-3; 1.
DR PANTHER; PTHR18860; 14-3-3; 1.
DR Pfam; PF00244; 14-3-3; 1.
DR PRINTS; PR00305; 1433ZETA.
DR ProDom; PD000600; 14-3-3; 1.
DR SMART; SM00101; 14_3_3; 1.
DR PROSITE; PS00796; 1433_1; 1.
DR PROSITE; PS00797; 1433_2; 1.
KW Acetylation.
FT CHAIN 1 244 14-3-3 protein beta/alpha.
FT /FTId=PRO_0000058600.
FT MOD_RES 1 1 N-acetylmethionine (By similarity).
SQ SEQUENCE 244 AA; 27721 MW; FF766793EA1CA9E5 CRC64;
MDKSELVQKA KLSEQAERYD DMAASMKAVT ELGAELSNEE RNLLSVAYKN VVGARRSSWR
VISSIEQKTE GNDKRQQMAR EYREKVETEL QDICKDVLGL LDKYLVPNAT PPESKVFYLK
MKGDYYRYLS EVASGDSKQE TVTCSQQAYQ EAFEISKSEM QPTHPIRLGL ALNFSVFYYE
ILNSPEKACS LAKSAFDEAI AELDTLNEES YKDSTLIMQL LRDNLTLWTS ENQGEEADNA
EADN
//Alignement de séquences
Un petit exemple didactique :
from Bio import Align
aligner = Align.PairwiseAligner()
seq1 = "GAACT"
seq2 = "GAT"
score = aligner.score(seq1, seq2)
score
3.0
alignments = aligner.align(seq1, seq2)
for alignment in alignments:
print(alignment)qui donne ceci :
GAACT
||--|
GA--T
<BLANKLINE>
GAACT
|-|-|
G-A-T
<BLANKLINE>BLAST bien sûr...
Biopython procure un accès commode à BLAST, le logiciel préféré des biologistes (avec EndNote). En fait la force de Biopython est de pouvoir manipuler des données de séquences biologiques par les différents logiciels classiques du domaine en effectuant les conversions de format et de conventions de passage de paramètres sans que le biologiste ait à s’en soucier.
#!/usr/bin/env python3
import sys
from Bio.Blast import NCBIWWW
from Bio.Blast import NCBIXML
def Blast_sonde(blastversion, collection, gi):
result_handle = NCBIWWW.qblast(blastversion, \
collection, gi)
blast_record = NCBIXML.read(result_handle)
E_VALUE_THRESH = 0.04
for alignment in blast_record.alignments:
for hsp in alignment.hsps:
if hsp.expect < E_VALUE_THRESH:
print("****Alignment****")
print("sequence:", alignment.title)
print("length:", alignment.length)
print("e value:", hsp.expect)
print(hsp.query[0:75] + "...")
print(hsp.match[0:75] + "...")
print(hsp.sbjct[0:75] + "...")
blastversion = sys.argv[1]
collection = sys.argv[2]
gi = sys.argv[3]
Blast_sonde(blastversion, collection, gi)Si on connaît l’identifiant GenBank, avec la ligne de commande :
./BLAST-biopython.py blastn nt 8332116
BLAST évalue la pertinence statistique du score par une analyse de la distribution des scores d’alignement entre la séquence-test et l’ensemble des séquences cibles, et calcule la probabilité et l’espérance mathématique de trouver un alignement donnant un score donné parmi les cibles, uniquement du fait du hasard. L’espérance mathématique est notée e-value.
****Alignment****
sequence: gi|1219041180|ref|XM_021875076.1| PREDICTED: Chenopodium quinoa
cold-regulated 413 plasma membrane protein 2-like (LOC110697660), mRNA
length: 1173
e value: 1.63199e-117
ACAGAAAATGGGGAGAGAAATGAAGTACTTGGCCATGAAAACTGATCAATTGGC ...
|| ||||||||| |||| | |||| || |||| |||| | |||| ||| | || ...
ACCGAAAATGGGCAGAGGAGTGAATTATATGGCAATGACACCTGAGCAACTAGC ...
****Alignment****
sequence: gi|1226796956|ref|XM_021992092.1| PREDICTED: Spinacia oleracea
cold-regulated 413 plasma membrane protein 2-like (LOC110787470), mRNA
length: 672
e value: 1.0299e-113
AAAATGGGGAGAGAAATGAAGTACTTGGCCATGAAAACTGATCAATTGGCCGT ...
|||||||| ||| |||| | || ||||| |||||||| || ||||| |||| ...
AAAATGGGTAGACGAATGGATTATTTGGCGATGAAAACCGAGCAATTAGCCGC ...
****Alignment****
sequence: gi|731339628|ref|XM_010682658.1| PREDICTED: Beta vulgaris subsp.
vulgaris cold-regulated 413 plasma membrane protein 2 (LOC104895996), mRNA
length: 847
e value: 2.76359e-108
TTGGCCATGAAAACTGATCAATTGGCCGTGGCTAATATGATCGATTCCGATAT ...
||||||||||||||||| ||| |||| |||||||| |||| |||| ||||| ...
TTGGCCATGAAAACTGAGCAAATGGCGTTGGCTAATTTGATAGATTATGATAT ...
****Alignment****
sequence: gi|1389679838|ref|XM_016034586.2| PREDICTED: Ziziphus jujuba
cold-regulated 413 plasma membrane protein 2-like (LOC107424728), mRNA
length: 946
e value: 1.43158e-105
AAAATGGGGAGAGAAATGAAGTACTTGGCCATGAAAACTGATCAATTGGCCGT ...
||||||||||| ||| ||| ||||| |||| |||||||| | ||| ...
AAAATGGGGAGG---ATGGAGTTTTTGGCTATGAGAACTGATCCA---GCCAC ...Apprend-on ainsi à programmer ?
Non bien sûr, on aligne des recettes sans comprendre leur mécanisme.
– L’expérience IHM (interface humain-machine) nous apprend qu’écrire une instruction est facile ;
– la preuve par le tableur : on apprend facilement à écrire des formules de calcul dans les cases, cependant que le logiciel fournit la charpente qui les assemble de façon cohérente ;
– décomposer un problème plus vaste en sous-problèmes est difficile ;
– d’où la propension à « faire ci et puis après faire ça ».
Ce qu’il faut enseigner, c’est donc la conception et la réalisation de sous-programmes, et leur assemblage.
C’est une bonne raison d’encourager le style fonctionnel, praticable avec la plupart des langages, mais certains l’encouragent plus que d’autres.
Tri Rapide en Python
#!/usr/bin/env python3
def tri_rapide (T) :
imin, imax = 0, len(T) - 1
tri_part(T, imin, imax)
return T
def tri_part(T, imin, imax) :
if imin < imax :
q = partition (T, imin, imax)
tri_part(T, imin, q)
tri_part(T, q + 1, imax)
def partition (T, imin, imax):
x = T[imin]
while True :
while T[imax] > x :
imax -= 1
while T[imin] < x :
imin += 1
if imin < imax :
echange (T, imin, imax)
imax -= 1
imin += 1
else :
return imax
def echange(V, i, j):
tmp = V[i]
V[i] = V[j]
V[j] = tmp
import sys
def lire_vecteur(fichier) :
f = open(fichier, mode = 'r')
T = f.readlines()
for i in range(len(T)) :
T[i] = int(T[i])
f.close()
return T
print (tri_rapide (lire_vecteur(sys.argv[1])))Tri Rapide en Scheme
Le programme ci-dessous accepte en paramètre d’entrée le nom d’un fichier qui contient la suite des nombres qui constituent le vecteur à trier. Ces nombres doivent être disposés selon la syntaxe des vecteurs de Scheme, c’est-à-dire précédés des caractères #( et suivis du caractère ).
(module tri-rapide-vecteur
(main lire-vecteur))
(define (lire-vecteur Args)
(let* ((fichier (cadr Args))
(influx (let ((s (file->string fichier)))
(open-input-string s )))
(V (read influx))
(longueurV (vector-length V)))
(close-input-port influx)
(multiple-value-bind (res rtime stime utime)
(time
(lambda ()
(tri-rapide V 0 (-fx longueurV 1))))
(print "real: " rtime " sys: " stime " user: " utime))
(do ((i 0 (+fx i 1)))
((=fx i longueurV))
(print (vector-ref V i))) ))
(define (tri-rapide v imin imax)
(if (<fx imin imax)
(let ((q (partition v imin imax)))
(tri-rapide v imin q)
(tri-rapide v (+fx q 1) imax)))
v)
(define (partition v imin imax)
(let ((x (vector-ref v imin)))
(let loop ()
(let loop1 ()
(if (>fx (vector-ref v imax) x)
(begin
(set! imax (-fx imax 1))
(loop1))))
(let loop2 ()
(if (<fx (vector-ref v imin) x)
(begin
(set! imin (+fx imin 1))
(loop2))))
(if (<fx imin imax)
(begin
(swap v imin imax)
(set! imin (+fx imin 1))
(set! imax (-fx imax 1))
(loop))
imax))))
(define (swap v i j)
(let ((x (vector-ref v i)))
(vector-set! v i (vector-ref v j))
(vector-set! v j x)))Comme ce programme était utilisé pour trier des vecteurs de nombres entiers, à l’incitation de Manuel Serrano j’ai utilisé les fonctions d’arithmétique entière explicites =fx +fx -fx <fx >fx, ce qui améliore considérablement les performances. Pour trier des valeurs d’autres types, tels que chaînes de caractères ou nombres en virgule flottante le programme devrait être modifié pour utiliser les fonctions de comparaison appropriées.
Ce programme utilise quelques autres facilités procurées par le compilateur Bigloo, utiles à la manipulation de grands volumes de données comme nous le verrons lorsque nous aborderons la question des mesures de performances.
Tri rapide en C
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
#include <time.h>
void quicksort(int tableau[], int premier, int dernier){
int i, j, pivot, temp;
if(premier < dernier){
pivot = premier;
i = premier;
j = dernier ;
while(i < j){
while(tableau[i] <= tableau[pivot] && i < dernier)
i++;
while(tableau[j] > tableau[pivot])
j--;
if(i < j){
temp = tableau[i];
tableau[i] = tableau[j];
tableau[j] = temp;
}
}
temp = tableau[pivot];
tableau[pivot] = tableau[j];
tableau[j] = temp;
quicksort(tableau, premier, j-1);
quicksort(tableau, j+1, dernier);
}
}
int comptemots(char* fichier){
FILE *inTube;
long nombreMots = 0;
char commande[64] = "wc -w ";
strcat(commande, fichier);
inTube = popen(commande, "r");
if (inTube != NULL) {
fscanf(inTube, "%ld", &nombreMots);
pclose(inTube);
}
// printf("%ld\n", nombreMots);
return(nombreMots);
}
int main(int argc, char* argv[]){
int x, i, nombreMots = 0;
long clk_tck = CLOCKS_PER_SEC;
clock_t t1, t2;
nombreMots = comptemots(argv[1]);
FILE *fp;
int *tableau = malloc(nombreMots * sizeof(int));
fp = fopen (argv[1], "r");
for (i = 0; i < nombreMots; i++){
fscanf(fp, "%d", &x);
*(tableau + i) = x;
}
fclose (fp);
t1 = clock();
quicksort(tableau, 0, nombreMots - 1);
t2 = clock();
for (i = 0; i < nombreMots; i++)
printf(" %d\n", tableau[i]);
free(tableau);
(void)printf("Nb ticks/seconde = %ld, Nb ticks depart : %ld, "
"Nb ticks final : %ld\n",
clk_tck, (long)t1, (long)t2);
(void)printf("Temps consomme (s) : %lf \n",
(double)(t2-t1)/(double)clk_tck);
return 0;
}Ce programme illustre la raison pour laquelle C n’est pas un langage adapté à l’enseignement de la programmation à des débutants : si la fonction quicksort est intelligible, même si la syntaxe n’est peut-être pas un modèle de lisibilité, main et comptemots sont parfaitement cryptiques. Or c’est avec ce genre de sujets que les informaticiens sont appelés à se débattre quotidiennement. J’ai fait appel à l’aide d’Emmanuel Lazard pour la solution de ces problèmes très techniques.
Quels systèmes de programmation pour l’enseignement ?
La vitesse des programmes produits pour tel ou tel langage avec tel ou tel système de programmation n’est pas le premier critère de choix d’un langage pour l’enseignement, mais il est bon de savoir si ce langage est utilisable de façon réaliste pour traiter des problèmes réels.
Je n’aime pas les environnements de programmation intégrés : ils procurent certes un premier abord facile pour l’étudiant, mais ils lui dissimulent les interactions avec le système d’exploitation et avec les fichiers, or dans la pratique quotidienne de l’informaticien ces interactions sont une des principales sources de difficultés, et il est donc indispensable de s’y frotter. Pour la même raison, il faut que les étudiants compilent leurs programmes, afin d’observer le comportement d’un programme exécutable doté de son vecteur d’état et de ses interfaces avec le monde extérieur. Bref, les interpréteurs sont des logiciels utiles pour mettre le pied à l’étrier, mais cette étape doit être franchie.
Les environnements de programmation intégrés encouragent un style médiocre, le laxisme et l’imprécision dans la déclaration des variables, le déplorable dialogue « entrer les données - calculer - afficher les résultats ».
Mesure de performances du tri rapide (QuickSort)
Pour donner une idée (partielle et rudimentaire) des capacités de quelques systèmes de programmation à traiter des problèmes réels j’ai choisi d’appliquer l’algorithme classique d’Anthony Hoare au tri rapide d’un tableau de 200 millions de nombres entiers tirés au hasard entre 0 et un milliard, avec les programmes dont le texte figure ci-dessus. Voici, à toutes fins utiles, le programme de génération du tableau :
(module creer-vecteur
(main creer-vecteur))
(define (creer-vecteur Args)
(let* ((taille (string->number (cadr Args)))
(V (make-vector taille 0))
(fichier (caddr Args))
(grandeur
(if (null? (cdddr Args))
10000
(string->number (cadddr Args))))
(flux (open-output-file fichier)))
(do ((i 0 (+ i 1)))
((= i taille)
(vector-for-each (lambda (n)
(display n flux)
(display " " flux))
V)
(close-output-port flux))
(vector-set! V i (random grandeur)))))Sans surprise, Python échoue sans message d’erreur explicite au bout d’une cinquantaine de minutes, mais il serait vain de s’en offusquer : les auteurs du langage préviennent que le langage ne procure pas la récursion terminale, et qu’ils ne garantissent rien au-delà d’une profondeur d’appel récursif de 1000.
De façon plus choquante plusieurs implémentations de Scheme échouent également, ce qui donne à craindre que ce ne soient pas de vrais compilateurs, mais plutôt qu’ils construisent des exécutables en embarquant l’interprète. Cela ne justifie pas vraiment l’échec, que la récursion terminale devrait éviter.
Restent le compilateur Bigloo et, comme point de référence, le compilateur gcc pour C. Le texte des programmes indique où sont pris les points de mesure, j’ai veillé à éliminer les temps d’entrées-sorties. Pour C j’ai essayé plusieurs méthodes, avec rusage et avec clock, il n’y a pas de différence sensible. Voici les résultats :
Bigloo (en millisecondes) :
real: 132800 sys: 6310 user: 73890
C :
Nb ticks/seconde = 1000000, Nb ticks depart : 93007566, Nb ticks final : 157970548
Temps consomme (en secondes) : 64.962982Le programme C est plus rapide, ce qui est logique parce que c’est un langage de plus bas niveau, mais Bigloo reste dans les mêmes ordres de grandeur, ce qui dénote un vrai compilateur optimisant. De toute façon ces mesures sont intrinsèquement approximatives, ne serait-ce que pour des phénomènes liés à l’usage du cache.
Danger des mesures de performances
Les performances indiquées ci-dessus ont été observées sur un ordinateur particulièrement lent : Acer Aspire XC-100, processeur AMD E1-1200, deux cœurs, 1,4 GHz, 18 W. Ainsi j’ai obtenu des valeurs numériques plus grandes, donc une meilleure précision. Et surout cela n’a pas trop chauffé.
J’ai imprudemment fait tourner ces programmes sur un petit ordinateur portable doté d’un processeur Intel Core I7 7500U, deux cœurs, 2,7 GHz. Mal m’en a pris : ultra-mince, mal ventilé, la chaleur dégagée par l’appareil a détérioré les lignes de commande de l’écran non démontable, il faudrait changer tout le dos, la réparation coûterait pratiquement le prix de l’ordinateur. Pensez-y quand vous ferez vos propres essais !
Avantages du style fonctionnel
– Le ralentissement des progrès de la vitesse des processeurs, le
recours aux GPU et d’autres facteurs stimulent le recours au calcul
parallèle ;
– garantir qu’une tâche ne modifiera pas l’état du système pris
comme hypothèse par une autre tâche est nécessaire au déterminisme
du calcul ;
– le style fonctionnel limite le recours à l’affectation et par là facilite
la satisfaction de cette condition.
Le marché florissant de la lambda-expression
Expedia did “over 2.3 billion Lambda calls per month” back in December 2016. That number jumped 4.5 times year-over-year in 2017 (to 6.2 billion requests) and continues to rise in 2018. Example applications include integration of events for their CI/CD platforms, infrastructure governance and autoscaling.